关于EMD的俩个假设:
IMF 有两个假设条件:
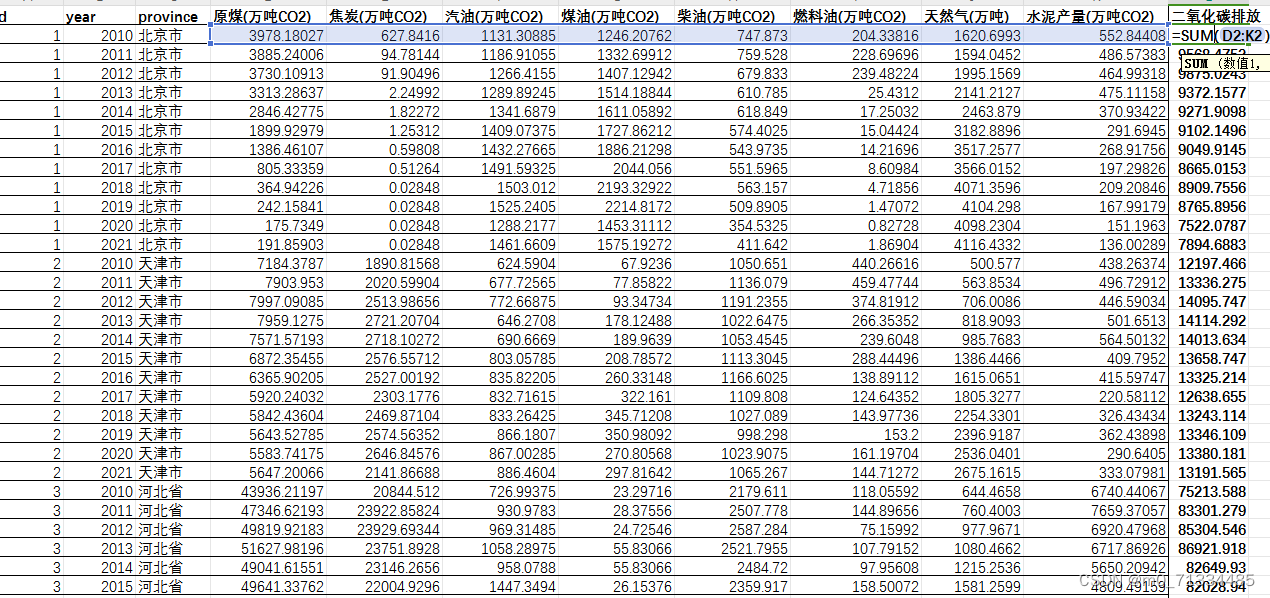
- 在整个数据段内,极值点的个数和过零点的个数必须相等或相差最多不能超过一 个;
- 在任意时刻,由局部极大值点形成的上包络线和由局部极小值点形成的下包络线 的平均值为零,即上、下包络线相对于时间轴局部对称。
先安装pyEMD库
from pyEMD import EMD (报错) 执行pip uninstall pyEMD pip install EMD-signal==1.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
代码部分:
from PyEMD import EMD
import numpy as np
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from scipy.signal import find_peaks
from scipy import signal
#读取信号数据
def readtxt(path):
with open(path,'r') as f:
str=f.readline()
list = str.split(' ')
list1=[];
for i,x in enumerate(list):
if ((i%5 == 0) or (i%5 == 1) or (i%5 == 2)) and x !='':
list1.append(float(x))
return list1
def pyem(lis):
emd = EMD()
IMFs = emd.emd(np.array(lis))
print(len(IMFs), len(IMFs[0]), type(IMFs))
#计算周期和频率
imfs = emd.imfs
# 估计瞬时频率和周期
freqs = []
periods = []
for imf in imfs:
if len(imf) > 1:
# 计算频率
sample_rate = 1 / (imf.argmax() / len(imf))
freq = sample_rate / len(imf)
print(freq)
freqs.append(freq)
# 计算周期
period = 1 / freq
print(period)
periods.append(period)
fig = plt.figure()
ax = fig.add_subplot(len(IMFs) + 1, 1, 1)
ax.plot(np.array(lis))
for i in range(len(IMFs)):
ax = fig.add_subplot(len(IMFs) + 1, 1, i + 2)
ax.plot(IMFs[i])
plt.show()
lr = 0
for i,s in enumerate(IMFs):
if i>len(IMFs-1)/2+1:
lr +=s
return lr
#获取心率
def findPeaks(list):
# x = electrocardiogram()[2000:4000]
# jus=[1,2,3,4,10,1,2,3,4,21,1,2,2,3]
#获取列表最小值,然后减去最小值
# list_N = list[20000:30000]
list_N = list
avg = sum(list_N)/len(list_N);
list_D=[]
for i in range(len(list_N)):
list_D.append(list_N[i]-avg)
#列表转换数组
y=np.array(list_D)
#消除趋势线
z=signal.detrend(y)
#结果抽取200点,降频,然后再获取数据的脉率
pl=200;
fs=len(list_N)
#参照值比
BP = fs/pl;
#进行趋势拟合
x=signal.resample(z,pl)
#获取最小值作为条件限制
hu=min(x)
peaks, _ = find_peaks(x, height=hu)
# print(peaks)
# 实际的心率值
# print(len(peaks))
##获取相邻俩个峰值之间的点数,然后计算心率值
for i,d in enumerate(peaks): #打印查看脉搏波的数值
print(peaks[i])
a1 = peaks[0]
a2 = peaks[1]
a3= a2-a1
#计算每个脉搏对应的点数
R_point = a3*BP
#以60为节点计算的数值
rate=60*(500/R_point)
# print("bass",bass)
#总的点数除以每一个脉搏对应的点数,然后除以90秒对应的值
# rate = (len(list)/R_point)/1.5
plt.plot(x)
plt.plot(peaks, x[peaks], "x")
plt.plot(np.zeros_like(x), "--", color="gray")
plt.show()
return rate
if __name__ == "__main__":
path = "../362a7e1de4dd484a9b4a3274a0e5a633_1648249928320.txt" #正常
# path = "../a7c9bff53f2e4a70af7a9f641552507a_1706541122_1706564288403_887_1.txt" #异常
ll = readtxt(path)
imf = pyem(ll[2000:10000])
plt.plot(imf)
plt.show()
print(findPeaks(imf))运行结果:
这是IMFS的分解图9个,从低频一直到高频

因为最后一个是趋势项,我们将IMF[5]、IMF[6]、IMF[7]进行叠加,这几本接近我们的目标信号
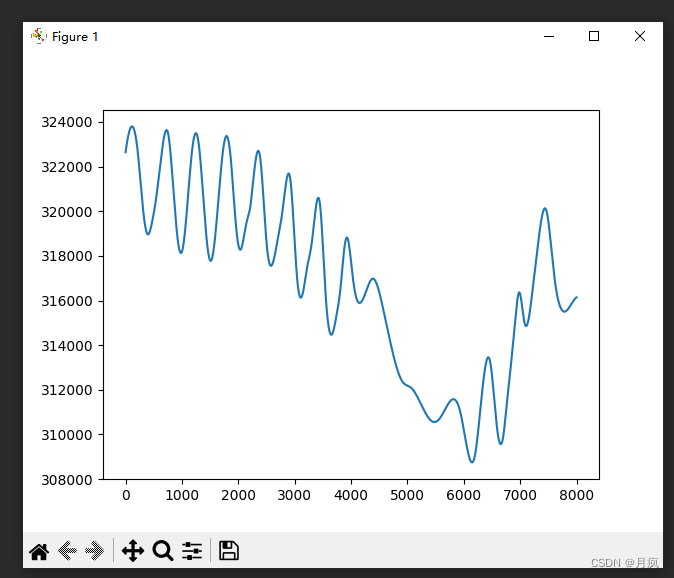
然后对目标信号进行峰值提取:
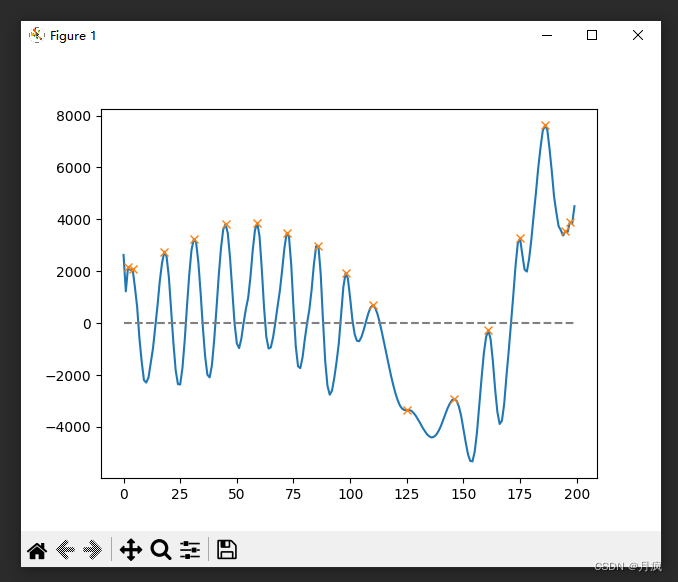
总结:
信号分量的处理
通过经验模态分解(EMD)得到了信号的分量,可以进行许多不同的分析和处理操作,以下是一些常见的对分量的利用方向:
(1)信号重构:将分解得到的各个本征模态函数(IMF)相加,可以重构原始信号。这可以用于验证分解的效果,或者用于信号的重建和恢复。
(2)去噪:对于复杂的信号,可能存在噪声或干扰成分。通过分析各个IMF的频率和振幅,可以识别和去除信号中的噪声成分。
(3)频率分析:分析每个IMF的频率成分,可以帮助理解信号在不同频率上的振荡特性,从而揭示信号的频域特征。
(4)特征提取:每个IMF代表了信号的局部特征和振荡模式,可以用于提取信号的特征,并进一步应用于机器学习或模式识别任务中。
(5)信号预测:通过对分解得到的各个IMF进行分析,可以探索信号的未来趋势和发展模式,从而用于信号的预测和预测建模。
(6)模式识别:分析每个IMF的时域和频域特征,可以帮助对信号进行模式识别和分类,用于识别信号中的不同模式和特征。
(7)异常检测:通过分析每个IMF的振幅和频率特征,可以用于探测信号中的异常或突发事件,从而用于异常检测和故障诊断。
在得到了信号的分量之后,可以根据具体的应用需求选择合适的分析和处理方法,以实现对信号的深入理解、特征提取和应用。